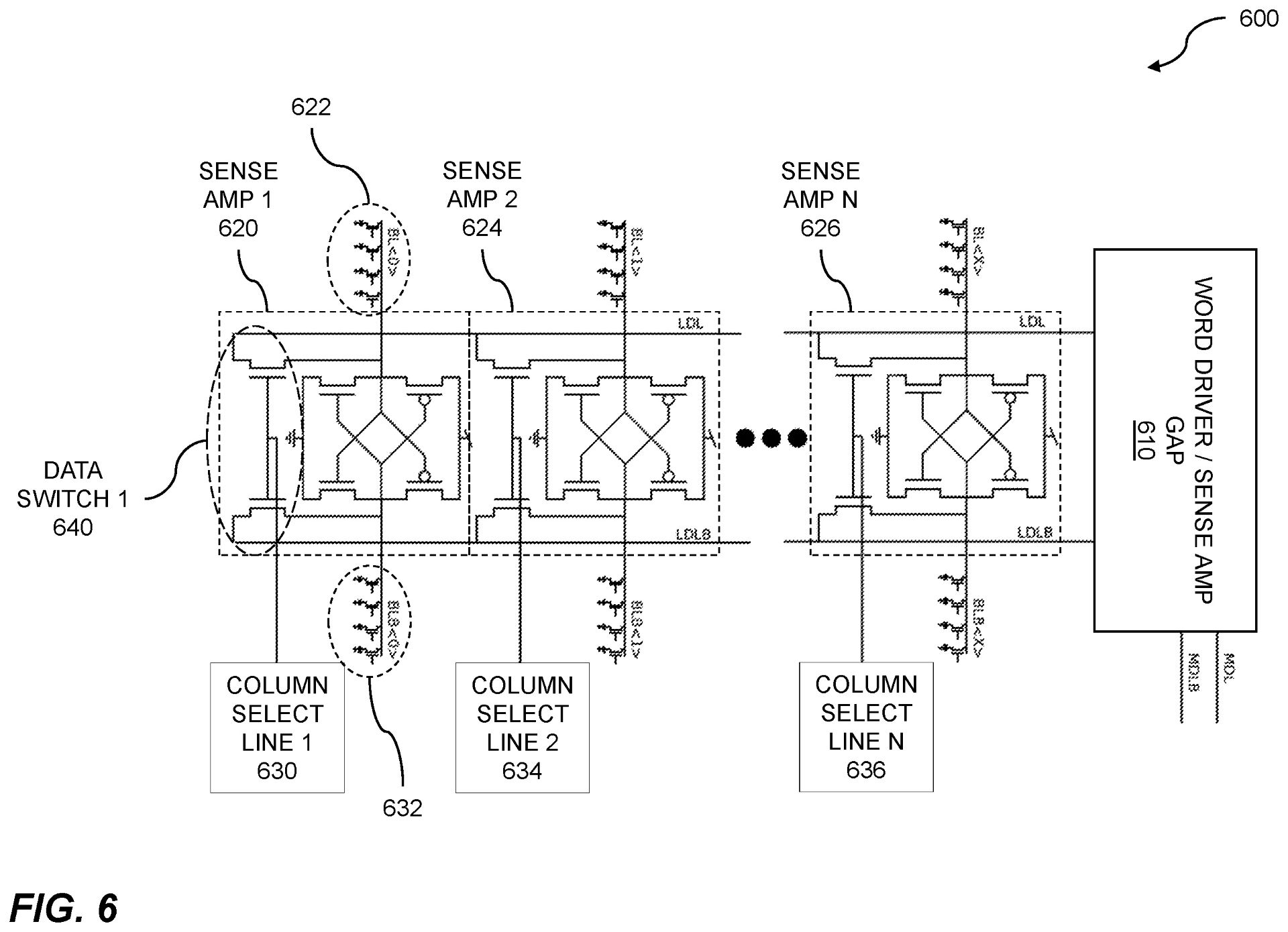
In-Memory Computing
Green Mountain Semiconductor has a long history in memory design, both from within the company itself and through the prior work experience of our skilled team. Since 2015 we have worked on in-memory computation with the aim to reduce power and increase performance. Our expertise with commodity memory product development led us to realize the potential to leverage the high parallelism inherent in the memory architectures.
We have worked on two consecutive NSF grants to develop IP around in-memory search and artificial intelligence algorithms embedded into the memory hardware.